
I am an assistant professor of computer science at the University of Illinois Chicago. Previously, I was a postdoc at the University of Zurich (with Sven Seuken) and Harvard SEAS (with David Parkes). Before that, I did my PhD at the University of Maryland, advised by John Dickerson and Tom Goldstein.
Most of my research focuses on situations where AI meets strategic incentives. This has included the use of machine learning for economic mechanism design (the main subject of my PhD thesis), adversarial robustness in deep learning, the study of optimal market-making strategies, and the incorporation of large language models into mechanism design, among other topics.
My CV is here. My Google Scholar page is here.Research interests
Below is a summary of some recent projects and research interests.Differentiable economics
A truthful, incentive compatible, or strategyproof economic mechanism is one where participants have no incentive to lie or otherwise behave strategically. (The classic truthful mechanism is a second-price auction, where the highest bid wins and pays the second-highest bid.) A grand challenge in mechanism design has been to design truthful auction mechanisms that maximize revenue. Myerson solved the problem for sales of a single item in 1981, and there has been very limited progress since then -- some results are known for selling multiple items to a single bidder, but even for selling two items to two agents, nothing is known beyond very simple special cases.
Duetting et al. published Optimal Auctions Through Deep Learning, which attempts to use the tools of deep learning to learn strategyproof mechanisms. The idea is to define a mechanism which is differentiable, and maximize revenue via gradient ascent. In limited settings, they can define architectures which will always be strategyproof; in more general settings, they define an architecture called RegretNet which can represent any auction, and incentivize strategyproofness by adding a term in the loss function.
Affine maximizer auctions
The ideal auction architecture for differentiable economics would be perfectly strategyproof, support multiple bidders and items, and be rich enough to represent any mechanism. Creating such an architecture remains difficult. There are single-bidder approaches (MenuNet, RochetNet) which are always strategyproof and can represent optimal mechanisms. RegretNet is multi-bidder and can approximate any mechanism, but is only approximately strategyproof. Our paper Differentiable Economics for Randomized Affine Maximizer Auctions presents an architecture that supports multiple bidders and is perfectly strategyproof, but cannot necessarily represent the optimal mechanism. This architecture is the classic affine maximizer auction (AMA) -- a reweighted form of the famous VCG mechanism -- now modified to offer lotteries. We are able to learn affine maximizer auctions that give good performance including in relatively large settings.Dynamic mechanism design
In our recent paper at AAAI '24, Automated Design of Affine Maximizer Mechanisms in Dynamic Settings, we extend the use of affine maximizers to dynamic mechanisms, where the mechanism must make a sequence of decisions over time on an MDP, and agents have different preferences over MDP outcomes. Dynamic variants of the VCG mechanism have been very thoroughly studied. Our focus is again on mechanism design for goals other than welfare, where theoretical progress has been relatively limited. In this setting, we face a challenging bilevel optimization problem, where the lower level involves finding reward-maximizing solutions in the MDP, and the upper level involves choosing affine maximizer parameters. We establish differentiability almost everywhere for the outer problem and show how to use gradient-based methods to find high-performing mechanisms in several dynamic mechanism design settings.Certifiably strategyproof auction networks
The RegretNet architecture may underestimate the degree to which strategyproofness is violated, as it uses a gradient-based approximation. Our NeurIPS 2020 paper Certifying Strategyproof Auction Networks adapts techniques from the adversarial robustness literature to exactly compute this quantity for a trained network. The idea is to embed the network itself in an integer program and directly solve a maximization problem for each player's utility.
Machine learning for matching and allocation
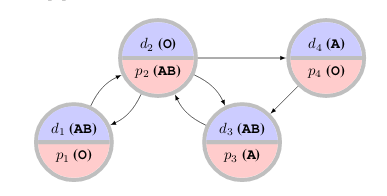
I have worked on applying machine learning to problems in matching and allocation. A particular application is to the kidney exchange problem, in which transplant patients and their willing but biologically-incompatible donors exchange kidneys, sometimes in cycles or long chains.
Although the problem is NP-hard there are reductions to integer programming allowing efficient solutions in practice. Kidney exchange networks have been very successful around the world, but there are still open research problems whose solutions could dramatically improve quality-of-life for the many patients still waiting for transplants.
One particular problem in kidney exchange is that patients and doctors are free to reject offered transplants, and often do, which can have cascading effects on other transplants. To avoid this, doctors are asked to pre-screen unacceptable transplants before matching takes place, but they only have time to screen a limited number. Our NeurIPS 2020 paper Improving Policy-Constrained Kidney Exchange via Pre-Screening formalizes and investigates the problem of finding the highest-leverage potential transplants to submit for pre-screening.
Adversarial machine learning
I have also participated in work on adversarial machine learning, including work on randomized smoothing for certifiably robust object detectors, and work on adversarial attacks on transfer learning systems.Reinforcement learning
In summer 2021, I was fortunate to intern at Salesforce Research, where I participated in a project on the use of multi-agent reinforcement learning to approximate economic equilibria in complex, heterogeneous simulation environments with multiple hierarchical levels of interacting agents.
Previous projects
Deep learning for Quantum Monte Carlo
In the summer of 2020, I participated in the G-RIPS program at the Institute for Pure and Applied Mathematics at UCLA. Our team was sponsored by AMD and focused on investigating the use of neural networks as approximate wavefunctions for many-electron quantum systems.
SI3-CMD DARPA grant
I was funded by a DARPA grant related to game theory. The focus of the project is a multiplayer version of classic influence maximization problems on social networks -- how should an advertiser spread their budget across the network, when dealing with multiple strategizing opponents trying to do the same thing?
It is possible to model this problem in a particularly nice way, resulting in a game which is socially concave. In socially concave games, when players individually update their strategies in a no-regret manner, they jointly reach a pure Nash equilibrium. My contributions have been to the applied side of the grant, dealing with the applications of the techniques to real-world graphs and concrete implementations of the no-regret algorithms using the mirror descent framework. This work resulted in the paper Scalable Equilibrium Computation for Multi-agent Influence Games on Networks at AAAI 2021.
Blog posts/notes:
- Auction Learning as a Two Player Game: GANS (?) for Mechanism Design (ICLR 2022 Blog Post Track)
- PPO and TRPO

